
Luck is a concept that probably exists in all the languages, a concept with elusive definition which we refer to in multiple situations. However, most of the times we do not have a clear idea of either we aim to refer to a sort of external intelligence loading the dice, or to a random event playing for or against us by chance. So, the question to be formulated will be, is luck (in the sense of “something” sorting out events in a positive or negative way) an invention of the human mind, insisting on finding an intelligent purpose behind the chains of events, or it is something else deserving an objective analysis?.
There are two irreconcilable stands on this matter, on the one hand those people thinking that luck has not any scientific evidence, and on the other hand those ignoring any scientific approach and believing that luck is a kind of intelligence, guiding the events in the interest of a specific eventual result. I wonder if there is room for analysis turning our backs on all the existing prejudices on this matter.
In this post I take the challenge to address the concept of luck. To that end I will be proposing firstly a definition, followed by introducing the orthodox science’s stand on the matter. Next I will explain why the abuse of the probabilistic approach is incorrect and finally, I will tell a couple of real stories challenging our common sense.
I will leave for a second post on the matter the introduction of some processes capable of creating real patterns in Nature on the one hand, and other mechanisms tricking us and making us recognise non-existent patterns on the other hand. To conclude I will dare to outline a couple of models aimed at explaining series of correlated events in life (luck).

A DEFINITION OF THE CONCEPT OF LUCK
Luck would not be more than the assessment of the eventual outcome of a chain of events and its subsequent classification as either positive or negative. According to this definition it comes clear that there is an important underlying subjective factor in the way in which we assess a series of events, in terms of being positive or negative for us. In order to get rid, as much as possible, of this subjectivity, I will be addressing only those chains of events clearly correlated in either a positive or negative way. Hence I will be discarding those chains of evens being positive or negative depending on a personal interpretation.
From the previous paragraph we can derive an equivalent definition, a bit more technical: luck would be a chain of events clearly correlated in an either positive or negative way. Let’s make clear here that such events should not be the outcome of a chain of bad or good decisions, leading to the corresponding negative or positive chain of results respectively. This point is key, if we want to analyse luck in an objective way, the objects under study would be those events strongly correlated but not attributable to be the consequence of a series of correlated causes. Generally speaking a linear relationship between a cause and its effect can be established as a simple, and linear, relation where the effect can be easily derived from a cause or input. Therefore, inputs and outputs are linked by means of an easy relationship. Not many things in life are linear, since we are surrounded by a lot of non-linear interactions making outputs not easily anticipated from specific causes. Let’s say that in a non-linear world the relation cause-effect does not exist. To a great extent this is what happens in our complex world, our linear brain keeps analysing (trying) a non-linear world. I would say that only in some specific circumstances our non-linear world comes linear and we can hence use easy rules to anticipate the effects following a cause. A linear brain in a non-linear world is a subject I will be addressing in another post. I only outline here these ideas to support the reasoning thread.
Therefore, the eventual definition for luck would be “a chain of events clearly correlated in an either positive or negative way and not attributable to be the outcome of a series of positive or negative causes respectively”.

WHERE DOES SCIENCE STAND ON LUCK?
Let’s be clear, science does not believe in either luck or in any intelligence ruling our fortune in the background. Science would study a chain of correlated events in a probabilistic way and always will end up stating that “the probability of such chain to happen is not zero, hence the correlation in the chain is a coincidence”. This is the key point, a chain of events (unless one or more of them violate a deterministic physical law as the law of gravity) will never have zero probability.
Even a huge chain of events strongly correlated will keep a probability different from zero. I find this fact quite tricky since while the common sense would be finding this phenomenon certainly suspicious, the probability theory will not be finding anything strange or violating any law.
In my opinion, the probabilistic approach is a sort of blank cheque denning sometimes suspicious facts. A glass just broken apart could, in theory, be pieced together spontaneously by a correlated chain of spontaneous thermal movements. The average time to observe that would be millions of years, but even if we witnessed that tomorrow the process would have non-zero probability.
A REASONABLE DOUBT
Let me play the role of a defence lawyer introducing some arguments for throwing a reasonable doubt on luck guilt.
The risks of applying the probabilistic approach to a process that we do not understand
Generally speaking, it is assumed that a series of events with non-zero probability is not impossible. It makes sense, however the underlying problem is when the probabilistic approach is applied to a non-random process (more technically non-stochastic process). Indeed, probabilistic approach should be applied to those processes with an underlying random dynamics, otherwise it may lead us to totally false conclusions.
Let me use as an example a well-known process determined by the so-called “logistic equation”. The logistic equation is studied in Chaos theory as an equation producing a deterministic process looking random. A deterministic process is that perfectly determined by previous conditions. Based on a given present state, the future evolution is perfectly pre-determined. The logistic equation is x(t+1)=r*x(t)*(1-x(t)) and describes a process in which given a known value of the variable x in time t, we know the next state x(t+1) in time t+1. x is a variable ranging within the interval [0,1] and r a fixed parameter that can be taken from the range [1, 4]. The interesting thing is that for certain values of the parameter r the chain of values looks really random, however it is completely deterministic. This finding was a great breakthrough in the field of dynamical systems (1).
The important thing here is how the probabilistic approach can lead us to false conclusions when applied to non-random underlying phenomena (even if they look random). Next figure shows a chain of values produced by the logistic equation when r=4.
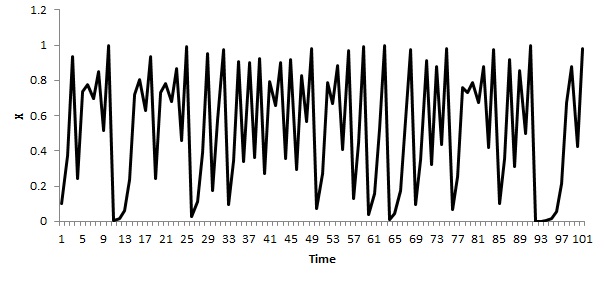
Now, if an observer considered that such chain of events is the outcome of a random process and decided to use the probabilistic approach, he/she would build the probability distribution of the variable X, by studying a chain long enough. The observer would obtain the following probability distribution (more precisely “frequency distribution”).

Now, if that observer took the chain of events from the figure 3 and tried to predict the next value by using the probability distribution in the figure 4, he/she would say that all the numbers in the range [0, 1] have certain probability to show up, being the values x=0.01 and x=1 the most probable with 0.06 probability. The probability distribution would provide all the probabilities associated to the different possible values of X. However, the last value in the chain in the figure 3 is 0.977658, and according to the logistic equation the next value is 0.08737, with probability equal to 1. That is to say, any value different from 0.08737 is impossible, however the probabilistic approach assigns all the range [0, 1] with some probability to happen.
The moral of this simple example is that the application of the probabilistic approach to processes whose underlying principles we do not know, can lead us to assign occurrence probability to events that actually are impossible.
When the events break the common sense but not the probability theory
Let us imagine now the process in the figure 3 as a real random process and the probability distribution in the figure 4 as the real description of the event occurrence. Next imagine that we get the sequence 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47, 0.47. The event 0.47 has an associate probability of 0.0017. The calculation of the probability of a sequence of events (when the events are considered independent among them) consists in the multiplication of the associated probability for each event present in the sequence. In this case, the probability of this chain is P=0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017 * 0.0017= 0.00000000000000000000000000000000000000000000486612
Here we have a problem, while the common sense tells us that something strange is happening, the probability theory indicates that this chain has no zero-probability, and as we are not breaking any law, we have a coincidence, not a meaningful occurrence. From the highly correlated chain of events, the common sense tells us that the process stopped being random and that a different dynamics took over. On the other hand, if we get stuck to the probabilistic approach, we will think that we have nothing else than a coincidence.
Which approach should we adopt?. My stand would be to use the probabilistic approach only if we were certain that the nature of the process is random and the process is isolated, I mean there is no chance that any other external condition may affect the evolution of the random process. In all the cases in which I could not ensure the previous conditions I would think of strongly correlated chains as patterns generated by no pure random dynamics. In my opinion it is better to admit that we are not certain of the underlying nature of the process that embracing an incorrect approach, only because it makes us feel that we have an interpretation. In other words, for me it is better to admit our ignorance that to embrace an erroneous idea to keep us away from uncertainty. As I mentioned in the post “Reality is a complex object (I)” human beings do not feel comfortable with uncertainty and tend to lie to themselves.
SOME REAL CASES AGAINST COMMON SENSE
Continuing with the analogy of a trial against luck and insisting in throwing a reasonable doubt on luck guilt, I show next a couple of real cases in which a highly correlated chain of events occur.
Never board with Hugh Williams
I would like to introduce an incredible story on a series of events that took place in the waters off the Welsh coast between the seventieth and ninetieth centuries. A ship sank in the Menai Strait, off the Welsh coast, with 81 passengers on board on December 5, 1664. Only one passenger survived, his name was Hugh Williams. Around one century after that shipwreck, in 1785, again on December 5, another ship with 60 passengers on board sank in the Menai Strait, the only survivor, was called Hugh Williams again. A third shipwreck with only one survivor called Hugh Williams took place in 1820, again on December 5th, when a vessel sank in the Manai Strait with 25 people on board.
You can find below a video explaining this story.

The unsinkable Hugh Williams
I came across this story some time ago and I investigated whether the data were accurate. I found an interesting blog by Rick Spilmanthe, novelist and sailor, where he sets out his research on this story (2). According to his research, very well documented by the way, it seems that the 1820 sinking happened on August 5th not December 5th. Additionally he introduces a new sinking on July, 10th 1940, when a British trawler was destroyed by a German mine. This time there were two survivors, both called Hugh Williams, uncle and nephew.
Next, the author sets out some arguments trying to explain this coincidence. He points out that the name Hugh Williams was not uncommon at that time, that the Menai Strait is a “nasty body of water with strong currents and rough seas” what makes usual have shipwrecks quite often in that exact area. He also states that the number of shipwrecks in that area was close to three hundred during that period. The author comes to the conclusion that given the previous arguments the series of three shipwrecks with the same results in a period of around 150 years is not such an incredible coincidence. His argument came sensible to me, but I decided to go a step forward and try to calculate the probability for that to happen, and see if we can consider this true story as coincidence against the common sense or not.
First of all I consider Rick’s argument valid and I do not consider as a coincidence the place in which the ships sank for being well known as a dangerous area. I will not have into consideration that two out of the three events took place on the same day of the year (December 5th) although it is clearly meaningful. I just want to get a preliminary result keeping the problem as simple as possible. Rick’s argument about Hugh Williams not being an uncommon combination of first and family names is interesting, and I will put it to the test by calculating the probability of these events to happen, for different rates of Hugh Williams in Wales population.
The exercise will consist in calculating the probability (do not get scare, I will not be including the technical details here, although I will be providing some additional comments in an annex at the end of this post) of, given certain rate of Hugh Williams in Wales, at least one of them is on board, combined with the event that only one passenger survives and he is called Hugh Williams. The value of this probability as a function of the proportion of Hugh Williams in Wales population is shown in the next figure.

Now I proceed to depict in the figure 6 the probability of having three shipwrecks with one surviving Hugh Williams each after observing 300 shipwrecks (number given by Rick) in those waters.

Finally, the figure 7 shows the number of periods (periods of 156 years), in average, necessary to observe three shipwrecks with a single survivor called Hugh Williams.

At this stage the reader must be wondering about the meaning of the arrows in the figures 5, 6 and 7. They point at the value 0.02% in all the cases. I am considering that value as a good reference for a highly common combination of name + family name. The reasoning behind that is as follows: I took a look at the most common first and family names in Spain, finding out that they are “Antonio” and “Garcia” with rates 1.58% and 2.9% respectively. We have then that the probability for a baby to be born in the bosom of a family called Garcia is 2.9%, being the probability to be a baby boy approximately 50% and the probability of being called Antonio 1.58%. Therefore, the probability to find randomly an Antonio Garcia would be the compound probability 2.9% * 50% * 1.58% = 0.02%, exactly the value the arrows are pointing at. Considering that any other population in the world would have similar rates for the most common combination of first + family names, we know where to look at when it comes to study our probabilistic problem with Hugh Williams.
From the figure 7 follows that for 0.02% we would need to observe, in average, 768914 periods of 156 years, that is to say, we should observe those waters during 119950540 years, what means close to 120 million years. I would say that this is an incredible coincidence. Even if it is possible from a probabilistic point of view, I would come to the conclusion that it looks like the dice are loaded.
Obviously, someone could argue that the proportion of Hugh Williams at that time were higher, but then objective studies on the Welsh census should be supplied to support such deviation from the typical rates nowadays. Even if we considered higher rates we find that for 0.1% (one Hugh Williams per 1000 people) the number of 156-year periods to be observed in average is close to 6700, that is to say, over a million years.
Additional details on the assumptions and probability calculations are shown in the annex at the end of this post, for those more interested in the technical details.
Never walk in the forest with Roy Sullivan
While the probability of being hit by lighting is really small, there are a few people who have been hit by lighting several times during their lifetime (3). The most remarkable case is that of Roy Sullivan (4) who was hit seven times. Even considering that Roy was a United States park ranger, with considerably higher hit probability, it looks quite weird to be hit seven times. He had the dubious honour of being registered in the Guinness World Records due to that reason. People tried to keep away from him and even his wife ended up abandoning him. He eventually committed suicide after falling into depression.
Although Major Summerford’s story (hit by lighting three times) may look less impressive I find it really shocking. He would be hit one more time after death, his tombstone was stroke by lighting and destroyed. The destroyed tombstone can be seen in the picture below.

SUMMARY
I finish this first post on luck here, although I will be posting the second half soon, aiming to cover most of the ideas I have on this matter. In this half I have provided a definition of luck as well as a view of where orthodox science stands on this slippery concept. I also talked about the risk of assuming a probabilistic approach to processes whose underlying principles are not well known, and how some occurrences in life challenge our common sense, even if they supposedly do not break any scientific law.
In the next post I will be talking about some natural processes, generators of real patterns and how other times our mind tricks us and makes us believe in non-existing patterns. I will also outline one or two models trying to explain the series of correlated events in life.
I would not like to say goodbye without sharing the fantastic song which has accompanied me during this post writing.

See you soon.
ANNEX. DETAIL ON HUGH WILLIAMS SHIPWRECKS PROBABILITY CALCULATION
Given certain proportion of Hugh Williams in Wales population, I calculated the probability of at least one of them on board of the first ship with 81 passengers. I will refer to that probability as P1. Then, given at least one Hugh Williams on board I calculated the probability for only one passenger (with a generic name) surviving the shipwreck. I will refer to this second probability as P2 and I will consider that the survival probability in that dangerous area is 3/(81+60+25), since we have only data on the survivors for those three shipwrecks. Then I calculated the probability, given a single survivor, of that survivor being called Hugh Williams (remember that we already had at least one Hugh Williams on board). Let’s call this probability P3. When we have three separate events with their corresponding probabilities (at least one Hugh Williams on board, a shipwreck with a single survivor and that survivor to be called Hugh Williams) and we want to calculate the probability of the three events to happen simultaneously we have just to multiply their probabilities. It is the so-called “compound probability of independent events”. Hence, we will have that the probability to have a shipwreck with a single survivor called Hugh Williams is P1*P2*P3. The calculation of P1 is a function of the proportion of Hugh Williams in Wales, from now forth referred as %HW and the number of passengers in the ship.
I calculated the probabilities for the three shipwrecks separately and then I averaged over the three shipwrecks for different values of %HW. This is the result shown in the figure 5.
For the calculations in the figure 6 I considered the period of 156 years with 300 shipwrecks and I calculated the probability that three of them had a single survivor called Hugh Williams within that period. For that purpose I use the binomial distribution (5).
Once obtained the probability value (P) for a number of events (three Hugh survivals) within a period of time (156 years), the average time to “see” such cumulative series of events is 1/P. This is what is shown in the figure 7, the number of 156-year periods to be observed before finding three shipwrecks with a surviving Hugh Williams each.
References
- May, R. M. [1976] “Simple Mathematical Models with very Complicated Dynamics,” Nature 261, 459-467
- http://www.oldsaltblog.com/2012/07/the-unsinkable-hugh-williams-truth-behind-the-legend/
- http://www.entreelcaosyelorden.com/2011/08/curiosidades-sobre-caidas-de-rayos-y-la.html
- https://en.wikipedia.org/wiki/Roy_Sullivan
- https://en.wikipedia.org/wiki/Binomial_distribution
Deja un comentario